2017年初,参考Beanstalkd的延迟任务管理机制,基于Redis实现了一个高并发、高性能、高可用的分布式延迟任务系统。在点餐、收银、支付等多个高并发产品中经受住了考验,先后经历了2次重构后于2019年以Grape项目开源,Github 项目地址:https://github.com/dinstone/grape 。
Grape 主要提供以下特性:
- 任务具备延时、过期重试、重试次数、预留时间等功能。
- 通过Vert.x异步IO提供高性能 HTTP Restful API。
- 任务调度支持毫秒级精度,0毫秒延迟,Redis损耗小。
- 具备横向扩展能力,丰富的业务和性能指标监控接口。
什么是延迟任务
想必大家都在网上购过物,比如,你在淘宝上买了件商品,收到货物后,即使你不主动去点 “确认收货”,经过若干天后,系统也会自动确认收货,完结订单。
这是怎么做到的呢?其实,这个背后隐藏着一个常用技术,就是延迟任务。顾明思议,我们把需要延迟执行的任务叫做延迟任务。
请注意,延迟任务不是定时任务,它们之间是有显著的区别:
- 定时任务有明确的触发时间,延迟任务没有。
- 定时任务有执行周期,而延迟任务在某事件触发后一段时间内执行,没有执行周期。
- 定时任务一般执行的是批处理操作的任务,而延迟任务一般是针对单个处理操作的任务。
延迟任务典型场景
使用延迟任务的典型场景有以下这些:
- 红包 24 小时未被查收,需要执行退款业务。
- 提交订单 30 分钟后,用户如果没有付钱,系统需要自动取消订单,归还库存。
- 直播时间快到了,需要给关注的用户发送消息,提醒上线。
- 支付完成后,需要异步回调通知业务系统的支付完成状态,在至少一次的QoS要求下,需要按指数幂退时间间隔延迟执行回调。
仔细审查这些业务场景,会发现每个业务处理都是在一定时间后执行特定的任务,而触发的时间不是固定的,如果做成定时任务来处理会很麻烦,而且时效和性能无法很好的保证。因此,创建一个解决此类问题的延迟任务系统才是最佳实践。
延迟任务系统的特性
- 延迟任务的生产和消费需要支持高并发、高性能、高可用。延迟任务的提交通常参与到核心的业务流程中,如果不能保证并发和性能,将对核心业务有影响。
- 延迟任务的生产需要支持重复提交,很多场景下可能会存在重试的情况。
- 延迟任务的消费需要支持可靠消费,也就是说要需要明确的知道是否成功执行了任务。通常,这需要系统在消费时暂存延迟任务信息,在执行成功后提交反馈。
- 延迟任务具备延时、自动重试、优先级等功能。
- 延迟任务系统需要具备横向扩展能力,丰富的业务和性能指标监控能力。
延迟任务系统的解决方案
基于以上特性要求,调研了一些现有开源方案: 领导:谁再用 Redis 实现过期订单关闭,立马滚蛋!
- RabbitMQ 通过死信和死信路由实现。无法保证时效性。
- DelayQueue 实现。需要自己实现可靠消费,不具备分布式能力,需要自己实现高可用。
- Beanstalkd 实现。延迟任务管理机制契合大部分特性。但由于不支持复制功能,服务存在单点问题且数据可靠性也无法满足。
- Disque 实现。Redis 作者开源的分布式内存队列。Disque 采用和 Redis Cluster 类似无中心设计,所有节点都可以写入并复制到其他节点。不管是从功能上、设计还是可靠性都是比较好的选择。但是2016年之后就不咋维护了,
在调研了以上开源实现后发现,要实现一个满足以上特性的通用延迟任务系统,最好是具备Beanstalkd的任务管理机制,同时又有Disque的横向扩展能力和高可用性。
很显然,没有一个开源方案是完整的。那么接下来的问题就变成了,是基于Beanstalkd做二次开发集成Disque特性,还是基于Disque做二次开发集成Beanstalkd的任务管理特性?
很显然,不管选择那种二开方案,都是一项艰巨的挑战(我们根本就不具备二开的能力),没有丝毫的犹豫,放弃二开,直接原创。
鉴于研究了Beanstalkd和Disque特性和实现机理,决定基于它们做个微原创,当时有2个方案:
第一个方案是包装Beanstalkd实例做成延迟任务Broker集群,在Broker中管理任务的路由和队列消费的容错处理,从而实现横向扩展和高可用。该方案需要对Beanstalkd实例横向扩展和宕机做自动感知,会引入过多的中间件和实现逻辑,实现复杂度太高,整个系统的可用性很难保证。
第二个方案是基于Redis,使用有序集合zset实现延迟任务队列,也就是说将Beanstalkd的队列管理机制基于Redis的数据结构实现一遍就好。实现相对第一个方案,开发工作量小,而且可用性由Redis来保证(相当于集成了Disque)。
所以,最终选择了第二个方案,自研基于Redis的分布式延迟任务系统。
设计与实现
核心概念
Grape中的核心概念有:
- Job :业务定义的延迟任务,有以下属性:
- id,任务ID,由业务系统指定,全局唯一。
- dtr (delay to run),任务延时运行时间,单位是毫秒。
- ttr (time to run),任务预期执行时间,单位是毫秒。超过 ttr 则触发任务重试。
- noe (number of executions),任务执行次数,默认从0开始,消费一次自增一。业务系统可以根据该属性做业务处理,如指数幂退调用等。
- data (job content),任务内容,字节数组。业务系统可以提交一些任务执行需要的参数,避免再次查询数据库准备数据。
-
Tube :同一个主题的延迟任务队列,用于区分和管理不同业务分组的延迟任务。
-
Broker :延迟队列代理,用于管理Tube集合的运行。
- Server :Grape服务实例,为指定 namespace 的Broker提供 Restfull 的 Job API、Tube API、管理API和管理UI。
整体架构设计

Grape 是一个无状态的HTTP服务,很容易横向扩展。业务系统可以通过7层负载均衡器访问Grape-Server集群。
-
Grape-Server主要由API处理器和Broker组件构成。
- Broker内部由Scheduler和Tube组件构成。
- Scheduler负责发现和加载Tube实例,以便更多的Broker实例分担Tube实例的管理压力,同时对外提供API服务。
- Tube组件是延迟任务的管理器,其内部维护了3个Sorted Set队列:Deleay Queue、Remain Queue、Failed Queue。根据延迟任务的生命状态机制,任务在各个队列之间流动。
- Redis存储主要包含了三类数据,分别是tube的名称集合、tube的队列模型和延迟任务模型。
- tube的名称集合,是一个Set类的集合,代表当前由多少可用的延迟队列。
- tube的队列模型,3个队列都是Sorted Set数据结构,Key是tube名称,数据是以延迟时间排序的任务ID。
- 延迟任务模型,每个任务是一个HashMap结构的数据,Key是任务ID,Value是任务的各个属性。
任务生命周期
Grape借鉴了Beanstalkd的任务管理机制,因此在Grape中,延迟任务可能处于四种状态之一:“delay”、“ready”、“remain”或“failed”。围绕任务状态的迁移动作,满足了很多通用场景对延迟任务的诉求。
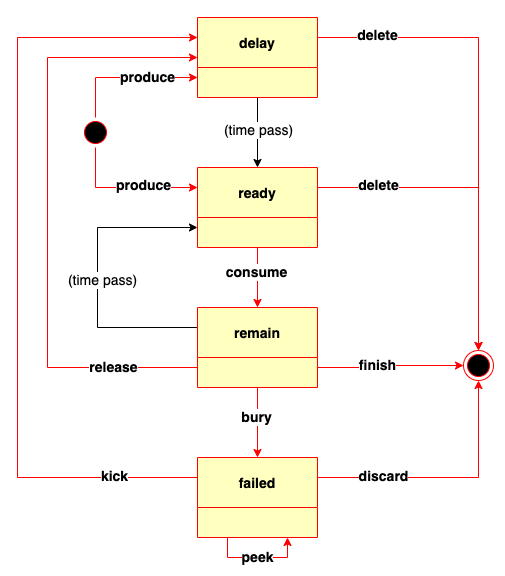
-
delay 状态,业务系统生成(produce)延迟任务后进入该状态。处于该状态的任务可以被删除(delete)。当前时刻大于任务延时后,任务迁移至ready状态。
-
ready 状态,业务系统生成(produce)延时为0毫秒的延迟任务进入该状态,或已过了延时的延迟任务进入该状态。进入该状态的任务可以被消费。消费任务(consume)将进入remain状态。
-
remain 状态,任务在消费期间会出现4种情况:
- 任务执行时间操过了ttr,或者执行任务的线程跑飞、业务进程宕机等异常情况下,任务会被调度到ready状态,使得任务可以被再次消费。
- 任务执行很顺利,但还没有拿到期望的结果,希望能再次重试,那么可以指定延时并释放(release)任务至delay状态。
- 任务执行很顺利,拿到了期望的结果,那么可以结束(finish)任务。
- 任务执行失败了,暂时无法处理,可能需要人工介入,可以先雪藏(bury)起来,则任务迁移至failed状态。
-
failed 状态,该状态的任务通常为异常任务,可通过查看(peek)任务来决策,如果需要继续执行,则打回(kick)到delay状态,如果不在需要执行,则可丢弃(discard)掉任务。
关键实现与技巧
更多的实现细节和技巧可以参阅源码工程,这里仅介绍2个关键实现和技巧。
1.Tube的队列模型
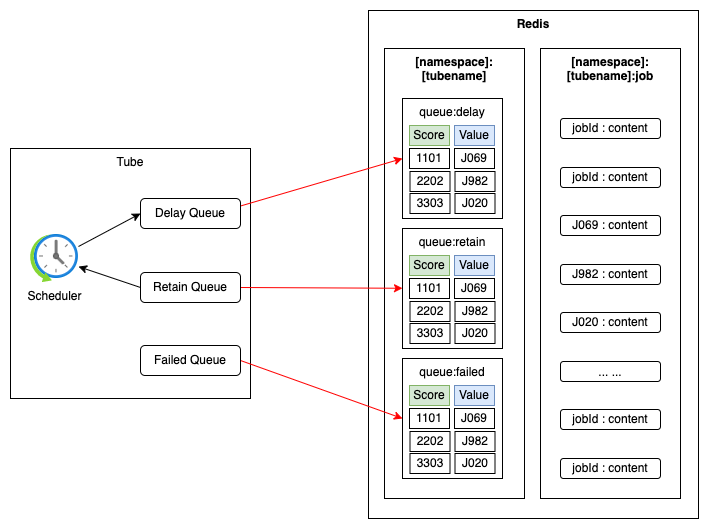
Tube中一共维护了3个队列,每个队列对应一个Redis的Sorted Set数据集合,Score是任务的延迟时间,Value是任务ID。
-
delay队列,存储delay和ready状态的延迟任务。produce提交的任务进入该队列后,不用做主动调度,就可以在consume的时候消费了。因为任务都是按延迟时间排序的,排在前面的任务,延时大于当前时间的都是ready的任务,所以是可以直接消费的。这样的实现即减少了调度的压力,也提升了调度的精度,而且也降低了Redis的IO。
-
retain队列,存储retain状态的任务。remain队列为什么也需要排序?对消费中的任务做ttr延迟时间排序,加快了retain状态到ready状态的转移。调度器不用扫描每个任务的ttr延时,通过Sorted Set数据结构可以直接获取remain队列的前n个到期任务。
-
failed队列,存储bury的任务。任务以提交时间排序,方便查看。
2.Broker的调度管理
Broker 作为延迟队列Tube的管理器,负责发现和执行Tube中任务的调度。
public Broker(RedisClient redisClient, String namespace, int scheduledSize) {
...
this.scheduledExecutor = Executors.newScheduledThreadPool(scheduledSize, new ThreadFactory() {
private final AtomicInteger index = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
return new Thread(r, threadPrefix + index.incrementAndGet());
}
});
}
Broker启动后,使用固定频率毎2秒执行一次检查,如果有新的Tube创建,那么就创建一个Tube的调度任务添加到调度器中,Tube的调度任务将以固定延迟时间来执行。这样就使得namespace下的所有Broker都负担起任务调度,提升了系统的性能和吞吐。
public Broker start() {
scheduledExecutor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
dispatch();
} catch (Exception e) {
LOG.warn("dispatch {} error: {}", namespace, e.getMessage());
}
}
}, 1, 2, TimeUnit.SECONDS);
LOG.info("Broker[{}] is started", namespace);
return this;
}
public Broker stop() {
scheduledExecutor.shutdown();
try {
scheduledExecutor.awaitTermination(Integer.MAX_VALUE, TimeUnit.HOURS);
} catch (InterruptedException e) {
}
LOG.info("Broker[{}] is shutdown", namespace);
return this;
}
private void dispatch() {
// discovery new tubes
Set<String> tubeSet = tubeSet();
for (String tubeName : tubeSet) {
if (!tubeTaskFutureMap.containsKey(tubeName)) {
ScheduledTask task = new ScheduledTask(createTube(tubeName));
ScheduledFuture<?> future = scheduledExecutor.scheduleWithFixedDelay(task, 0, 1, TimeUnit.SECONDS);
tubeTaskFutureMap.put(tubeName, future);
}
}
// remove old tubes
for (Iterator<Entry<String, ScheduledFuture<?>>> iterator = tubeTaskFutureMap.entrySet().iterator(); iterator
.hasNext();) {
Entry<String, ScheduledFuture<?>> next = iterator.next();
if (tubeSet.contains(next.getKey())) {
continue;
}
// cancel tube scheduled task
next.getValue().cancel(true);
// delete tube task future
iterator.remove();
}
}
private final class ScheduledTask implements Runnable {
private final Tube tube;
private ScheduledTask(Tube tube) {
this.tube = tube;
}
@Override
public void run() {
tube.schedule();
}
}
总结与未来规划
在我们的使用场景中,2个Broker实例和一个2G内存的Redis实例就能够支撑千万级的延迟任务,经受住了业务系统峰值1500TPS的考验。
当前业务指标的监控仅有任务队列的堆积数量,技术指标还不是很完善。未来期望在监控指标和可视化方面做更多的设计和实现。
延迟任务系统作为互联网应用的常用基础设施,推荐每位工程师、架构师和技术管理者都能了解它。
最后,欢迎大家来关注和使用Grape,更加欢迎 Issue 和 PR。项目地址:https://github.com/dinstone/grape 。