前言
不同于其它 MQ,Kafka 采用分区机制来提升系统的吞吐量。我们知道,要想提升 Kafka 的生产速率,直接增加生产者就可以了,那么要想提升消费速率,是否也是直接增加消费者就可以了呢?今天就生产中在用的多线程消费方案共享出来,以飨读者。
首先回顾一下 Kafka 的消费模式,我们知道 Kafka 的队列模式(P2P 模式、广播模式)是通过消费组(Consumer Group)概念来实现的,即每个 Consumer Group 所订阅 Topic 的每个 Partition 只能分配给该 Group 下的一个 Consumer 实例来消费,当然该 Partition 还可以被其他 Consumer Group 的 Consumer 实例来消费。站在同一个 Consumer Group 的角度来看,一个 Partition 只能被该 Consumer Group 里的一个 Consumer 实例消费。
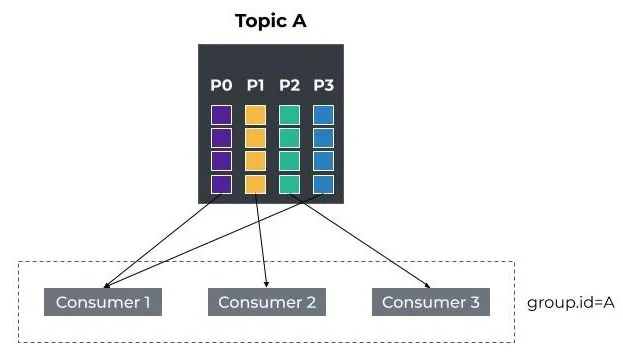
由上可知,Topic 的消费能力取决于每个 Consumer Group 的消费并行能力,Consumer Group 的消费并行能力取决于消费实例个数,而消费实例个数依赖于其所订阅的 Topic 配置的 Partition 数量,消费实例数只能小于等于 Partition 数量,比如 Partition 数量为 4,那么最多只能有 4 个消费实例来并行消费,如果超过了 4 个,只会浪费系统资源,因为多出的消费实例不会被分配到任何 Partition。
那么我们想要提升消费速率该怎么办呢?自然的想法就是增加 Topic 的 Partition 数量,然后能够启动更多的消费实例,从而提升消费速率。这种方式不可避免的需要涉及到数据迁移。如果不想增加 Partition 的数量(保持现有 Partition 数量的基础上),进一步提升 Kafka 消费并行能力,该怎么办呢?多线程消费无疑是个不错的想法。
设计
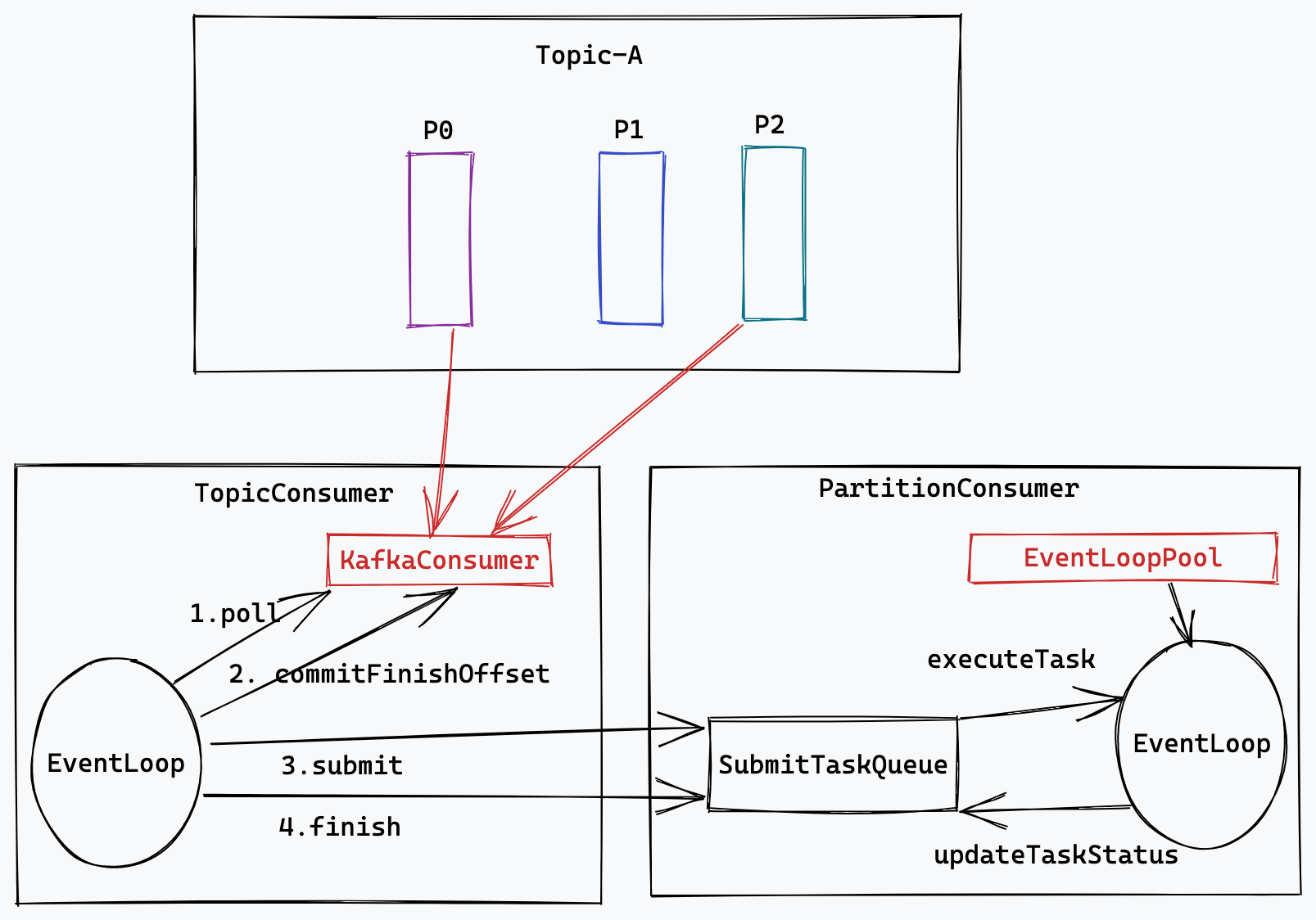
我们将 kafka 并行消费的职责封装在 2 个类中,一个是 TopicConsumer,一个是 PartitionConsumer。TopicConsumer 负责订阅和消费指定 Topic 中的消息,并将拉取到消息分发到相应的 PartitionConsumer 中执行,同时还要保证消费的速率和消费的可靠性。PartitionConsumer 则负责具体任务的并行执行和任务状态的维护。
Kafka 多线程并行消费主要有 2 个挑战:
-
速率控制,拉取速率和任务执行速率要匹配。可以使用 KafkaConsumer 的 seek、pause 和 resume 方法达到目的。
-
可靠消费,防止消息丢失和尽量少的重复消费。在 Consumer Group 的 Rebalance、服务重启等异常场景下消息不丢和不重。这里采用手动 ACK 和批量提交算法来实现。
具体参见如下代码实现。
实现
TopicConsumer 类。构造方法初始化 kafkaConsumer 的配置,构造 Eventloop 对象 TopicConsumerRunner。
public TopicConsumer(ConsumerConfig consumerConfig, MessageHandler<K, V> messageHandler,
Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
String topic = consumerConfig.getTopic();
if (topic == null || topic.length() == 0) {
throw new IllegalArgumentException("kafka.topic is empty");
}
// set auto commit = false
consumerConfig.setAutoCommit(false);
// create topic consumer runner
this.topicConsumeRunner = new TopicConsumeRunner(consumerConfig);
}
public void start() {
LOG.info("start topic[{}] consume process", consumerConfig.getTopic());
topicConsumeRunner.start();
}
public void stop() {
LOG.info("stop topic[{}] consume process", consumerConfig.getTopic());
topicConsumeRunner.close();
}
TopicConsumerRunner 类是 TopicConsumer 的内部类,run 方法是核心。
private class TopicConsumeRunner extends Thread {
private final Map<TopicPartition, PartitionConsumer<K, V>> partitionConsumers = new HashMap<>();
private final AtomicBoolean closed = new AtomicBoolean(false);
private ConsumerRebalanceListener rebalanceListener;
private Consumer<K, V> kafkaConsumer;
private long pollTimeOut;
public TopicConsumeRunner(ConsumerConfig consumerConfig) {
this.pollTimeOut = consumerConfig.getPollTimeOut();
// Thread name
setName("Topic[" + consumerConfig.getTopic() + "]-Poller");
// 通过RebalanceListener来管理PartitionConsumer的声明周期
this.rebalanceListener = new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
LOG.info("Revoke: {}}", partitions);
try {
commitFinishOffset();
} catch (Exception e) {
LOG.warn("Revoke commit offset error {}", e.getMessage());
// kafka comsumer is invalid, so must close partition consumer.
closePartitionConsumers();
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
LOG.info("Assign: {}}", partitions);
// resume consuming
kafkaConsumer.resume(partitions);
// create new partition consumers
Map<TopicPartition, PartitionConsumer<K, V>> newConsumers = new HashMap<>();
for (TopicPartition partition : partitions) {
PartitionConsumer<K, V> consumer = partitionConsumers.get(partition);
if (consumer == null) {
newConsumers.put(partition,
new PartitionConsumer<K, V>(partition, consumerConfig, messageHandler));
} else {
newConsumers.put(partition, consumer);
}
}
// clear revoked partition consumers
partitionConsumers.forEach((partition, consumer) -> {
if (!newConsumers.containsKey(partition)) {
// need to shutdown
consumer.shutdown();
}
});
partitionConsumers.clear();
// add new partition consumers
partitionConsumers.putAll(newConsumers);
// show partition state info
partitionConsumers.forEach((partition, consumer) -> {
OffsetAndMetadata osm = kafkaConsumer.committed(partition);
long committed = osm == null ? -1 : osm.offset();
long position = kafkaConsumer.position(partition);
long submit = consumer.submitOffset();
long finish = consumer.finishOffset();
LOG.info("{} commited={}, position={} ; submit={}, finish={}", partition, committed, position,
submit, finish);
});
}
};
}
public void run() {
// init kafka consumer
createKafkaConsumer();
Duration ptoMillis = Duration.ofMillis(pollTimeOut);
while (!closed.get()) {
long stime = System.currentTimeMillis();
try {
// 拉取已订阅Topic的消息
ConsumerRecords<K, V> records = kafkaConsumer.poll(ptoMillis);
LOG.debug("{} poll records size {}", topicName, records.count());
// 计算并提交已完成消息的offset
commitFinishOffset();
// 按照Partition提交到相应PartitionConsumer中
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<K, V>> recordList = records.records(partition);
LOG.debug("{} poll records size {}", partition, recordList.size());
PartitionConsumer<K, V> pc = partitionConsumers.get(partition);
// submit records and control rate
long count = pc.submit(recordList);
if (count > 0) {
// 将该partition的拉取offset重定向到提交位置
kafkaConsumer.seek(partition, pc.submitOffset() + 1);
}
// full check and pause consuming
if (pc.isFull()) {
// 先暂停该partition的消费
kafkaConsumer.pause(Collections.singleton(partition));
}
}
} catch (Exception e) {
// Ignore exception if closing
if (closed.get()) {
continue;
}
LOG.warn("create a new KafkaConsumer for topic {} by error : {}", topicName, e.getMessage());
closeKafkaConsumer();
createKafkaConsumer();
}
long etime = System.currentTimeMillis();
if (etime - stime < pollTimeOut) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
break;
}
}
}
closeKafkaConsumer();
}
private void commitFinishOffset() {
partitionConsumers.forEach((partition, consumer) -> {
// process finish offset
long count = consumer.finish();
if (count > 0) {
// sync ack commit offset
long offset = consumer.finishOffset() + 1;
OffsetAndMetadata cos = new OffsetAndMetadata(offset);
kafkaConsumer.commitSync(Collections.singletonMap(partition, cos));
}
// full check and pause consuming
if (!consumer.isFull()) {
// 恢复该partition的消费
kafkaConsumer.resume(Collections.singleton(partition));
}
});
}
private void createKafkaConsumer() {
kafkaConsumer = consumerFactory.createConsumer();
kafkaConsumer.subscribe(Arrays.asList(topicName), rebalanceListener);
}
private void closeKafkaConsumer() {
if (kafkaConsumer != null) {
kafkaConsumer.unsubscribe();
kafkaConsumer.close();
kafkaConsumer = null;
}
// shutdown and clear partition consumer
closePartitionConsumers();
}
private void closePartitionConsumers() {
partitionConsumers.forEach((tp, pc) -> {
pc.shutdown();
});
partitionConsumers.clear();
}
// Shutdown hook which can be called from a separate thread
private void close() {
closed.set(true);
if (kafkaConsumer != null) {
kafkaConsumer.wakeup();
}
}
}
PartitionConsumer 类:
public PartitionConsumer(TopicPartition partition, ConsumerConfig consumerConfig,
MessageHandler<K, V> messageHandler) {
this.partition = partition;
this.messageHandler = messageHandler;
this.messageQueueSize = consumerConfig.getMessageQueueSize();
int parallelSize = consumerConfig.getParallelConsumerSize();
this.executor = Executors.newCachedThreadPool();
for (int i = 0; i < parallelSize; i++) {
this.executor.execute(new RecordConsumeRunner(i));
}
}
public long submitOffset() {
return submitOffset;
}
public long finishOffset() {
return finishOffset;
}
public boolean isFull() {
return futureQueue.size() >= messageQueueSize;
}
/**
* submit record to consume
*
* @param <K>
* @param <V>
* @param recordList
* @return offset last submit
*/
public long submit(List<ConsumerRecord<K, V>> recordList) {
int count = 0;
ConsumerTask<K, V> last = null;
for (ConsumerRecord<K, V> record : recordList) {
if (!isFull()) {
last = new ConsumerTask<K, V>(record);
futureQueue.add(last);
submitQueue.add(last);
//
count++;
}
}
if (last != null) {
submitOffset = last.record().offset();
}
LOG.debug("{} submit count {}, last offset {}", partition, count, submitOffset);
return count;
}
/**
* find last finish offset
*
* @return offset first finish
*/
public long finish() {
int count = 0;
ConsumerTask<K, V> last = null;
for (;;) {
ConsumerTask<K, V> check = futureQueue.peek();
if (check == null || !check.isComplete()) {
break;
}
last = futureQueue.poll();
//
count++;
}
if (last != null) {
finishOffset = last.record().offset();
}
LOG.debug("{} finish count {}, last offset {}", partition, count, finishOffset);
return count;
}
public void shutdown() {
shutdown.set(true);
executor.shutdownNow();
LOG.info("{} consumer shutdown, submit/future: {}/{} tasks untreated, submit/finish: {}/{} offset", partition,
submitQueue.size(), futureQueue.size(), submitOffset, finishOffset);
}
RecordConsumeRunner 类:
private class RecordConsumeRunner implements Runnable {
private String tname;
public RecordConsumeRunner(int index) {
this.tname = "Partition[" + partition + "]-Work-" + index;
}
@Override
public void run() {
Thread.currentThread().setName(tname);
ConsumerTask<K, V> task = null;
while (!shutdown.get() && !Thread.interrupted()) {
try {
task = submitQueue.take();
messageHandler.handle(task.schedule());
task.complete();
} catch (Throwable e) {
if (task != null) {
task.complete(e);
}
// InterruptedException break, other ignore
if (e instanceof InterruptedException) {
break;
}
}
}
}
}
测试
public class TopicProducerTest {
public static void main(String[] args) {
ProducerKafkaConfig config = new ProducerKafkaConfig("config-producer-test.xml");
TopicProducer<String, String> producer = new TopicProducer<String, String>(config);
long st = System.currentTimeMillis();
int count = 100;
for (int i = 0; i < count; i++) {
producer.send("" + i, "a" + i);
}
producer.flush();
long et = System.currentTimeMillis();
System.out.println("ok," + count + " take's " + (et - st) + ", " + count * 1000 / (et - st) + "tps");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
producer.destroy();
}
}
public class TopicConsumerTest {
private static final Logger LOG = LoggerFactory.getLogger(TopicConsumerTest.class);
public static void main(String[] args) {
MessageHandler<String, String> handleService = new MessageHandler<String, String>() {
@Override
public void handle(ConsumerRecord<String, String> consumerRecord) throws Exception {
Thread.sleep(new Random().nextInt(10) * 1000);
LOG.error("{}-{} record: {}", consumerRecord.topic(), consumerRecord.partition(), consumerRecord.key());
}
};
ConsumerKafkaConfig consumeConfig = new ConsumerKafkaConfig("config-consumer-test.xml");
// consumeConfig.setParallelConsumerSize(1);
// consumeConfig.setMessageQueueSize(3);
TopicConsumer<String, String> process = new TopicConsumer<String, String>(consumeConfig, handleService);
process.start();
try {
System.in.read();
} catch (IOException e) {
}
process.stop();
}
}
总结
更多详情请访问代码工程,3分钟搭建测试环境并运行测试代码,感受真正的并行消费的魔力。地址:https://github.com/dinstone/kafka-assistant